Columns
| Column | Type | Size | Foreign Key | Nullable | Default | Comments |
|---|---|---|---|---|---|---|
| analysis_id | bigserial | 19 |
|
nextval('chado.analysis_analysis_id_seq'::regclass) | ||
| name | varchar | 255 |
|
√ | null | A way of grouping analyses. This should be a handy short identifier that can help people find an analysis they want. For instance "tRNAscan", "cDNA", "FlyPep", "SwissProt", and it should not be assumed to be unique. For instance, there may be lots of separate analyses done against a cDNA database. |
| description | text | 2147483647 |
|
√ | null | |
| program | varchar | 255 |
|
null | Program name, e.g. blastx, blastp, sim4, genscan. |
|
| programversion | varchar | 255 |
|
null | Version description, e.g. TBLASTX 2.0MP-WashU 09-Nov-2000. |
|
| algorithm | varchar | 255 |
|
√ | null | Algorithm name, e.g. blast. |
| sourcename | varchar | 255 |
|
√ | null | Source name, e.g. cDNA, SwissProt. |
| sourceversion | varchar | 255 |
|
√ | null | |
| sourceuri | text | 2147483647 |
|
√ | null | This is an optional, permanent URL or URI for the source of the analysis. The idea is that someone could recreate the analysis directly by going to this URI and fetching the source data (e.g. the blast database, or the training model). |
| timeexecuted | timestamp | 29,6 |
|
now() |
Table contained -1 rows
Indexes
| Constraint Name | Type | Sort | Column(s) |
|---|---|---|---|
| analysis_pkey | Primary key | Asc | analysis_id |
| analysis_c1 | Must be unique | Asc/Asc/Asc | program + programversion + sourcename |
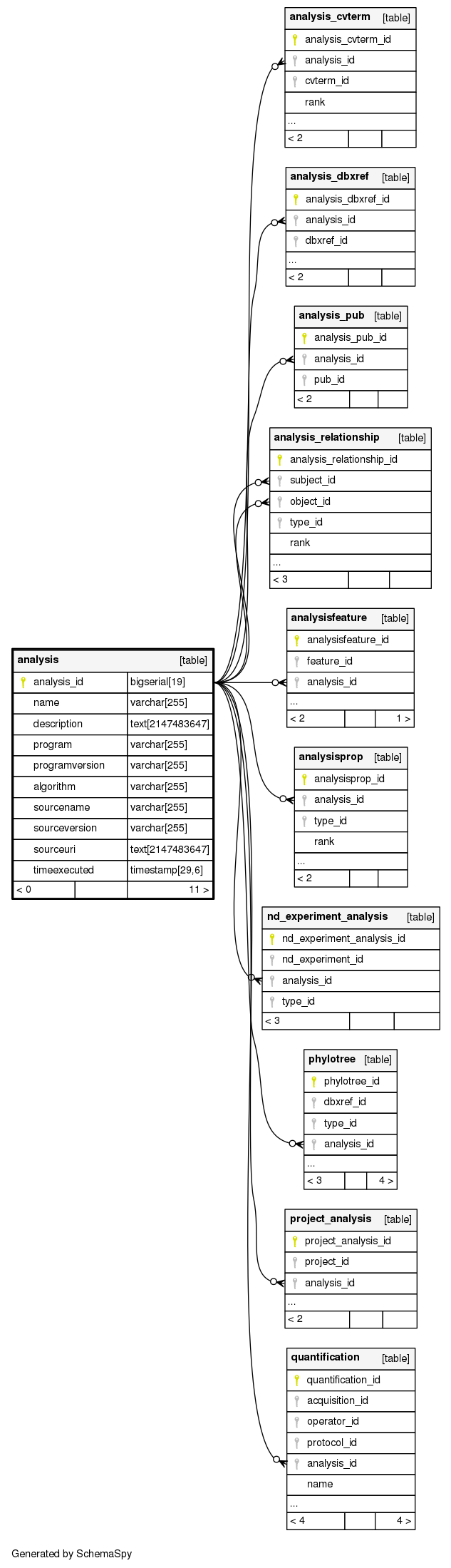
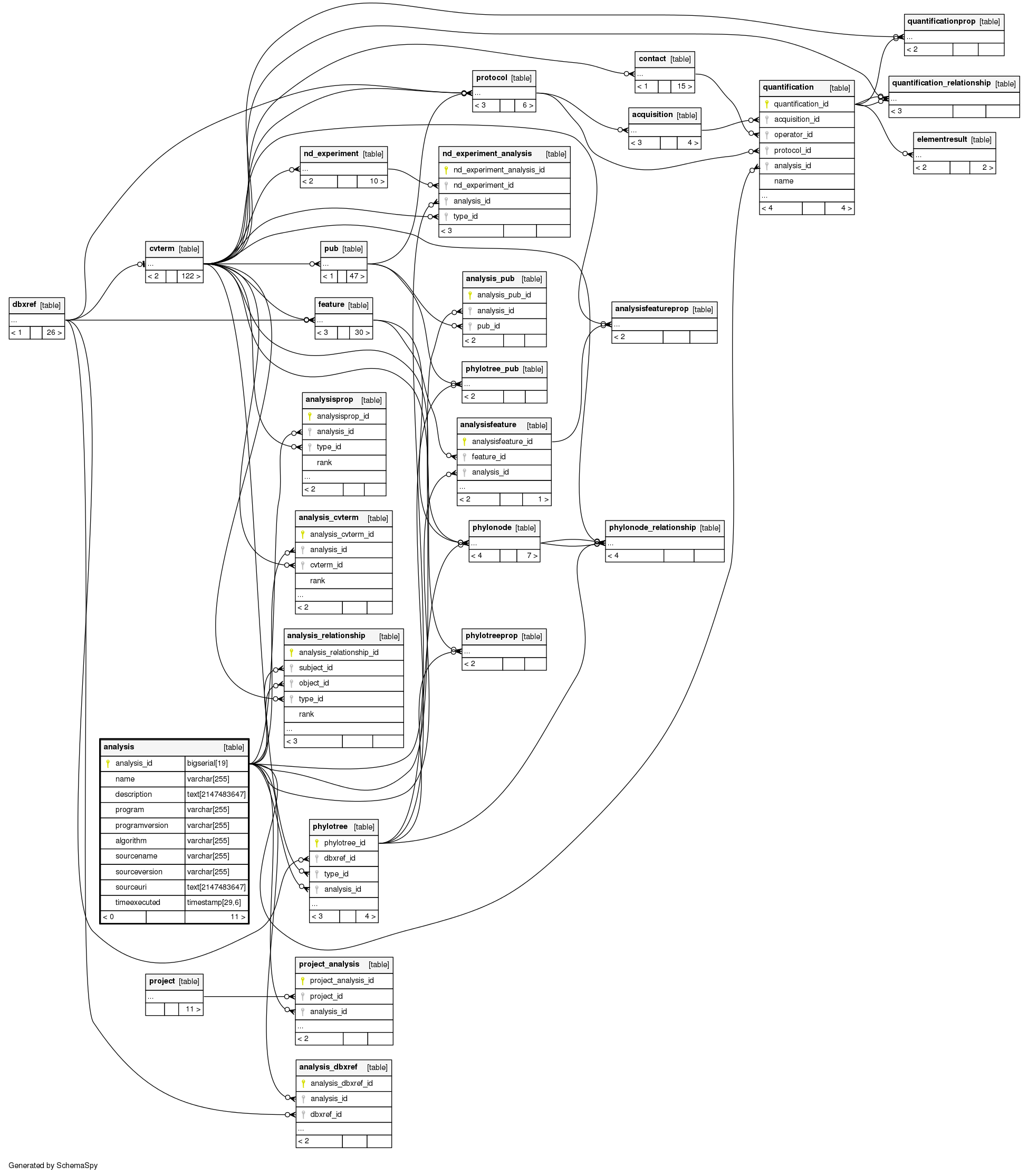
Relationships
The following entity relationship (ER) diagram shows the relationships involving the analysis table.
Show relationships within degrees of separation